A New Benchmark Driving Us Towards AGI
Reaching AGI
There are many benchmarks that serve the purpose of evaluating AI systems. So, what sets ARC-AGI-2 apart?
- Most existing benchmarks focus solely on PhD++level skills, typically showcasing superhuman capabilities in specific domains.
- ARC-AGI-2, however, evaluates AI systems on tasks that are extremely difficult—or even impossible—for AI to solve but are easily manageable for humans.
This shift in focus introduces a benchmark that could significantly impact the path toward AGI.
What is AGI?
Definition:
- AGI (Artificial General Intelligence) refers to intelligence capable of performing a wide range of tasks as well as a human.
Current Status:
- Advanced LLMs may exceed human performance in specific domains (e.g., PhD-level skills) but lack the general intelligence comparable to humans.
Why AGI Matters:
- AGI could serve humanity in key fields such as:
- Medical advancements
- Technological innovations
- Creative problem-solving
Tools for AGI:
AGI will need access to context-specific tools to perform tasks effectively.
For instance:
- Asking an LLM to compute
39847465 × 476139without reasoning capabilities may lead to hallucinations. - With a Python interpreter or web tools, the LLM can deliver precise results.
What Are LLMs?
Simple Explanation:
- LLMs (Large Language Models) are prediction-based systems.
- Unlike traditional programs that provide factual outputs, LLMs predict what the output might be based on their training.
Benchmarks and Model Improvement
Current Benchmarks:
- Focus areas: Coding, mathematical reasoning, creative skills, etc.
- Limitation: Rapid advancements in AI have outpaced these benchmarks. They no longer effectively measure the intelligence of newer systems.
Introducing ARC-AGI-2
What Makes It Unique:
- Focus on Human-AI Gap: Evaluates tasks hard for AI but manageable for humans within two attempts.
- Contrasting Traditional Benchmarks: Prioritizes what humans can do easily over domain-specific superhuman skills.
Significance:
ARC-AGI-2 measures gaps in general intelligence that cannot be bridged by simply scaling existing LLMs.
It highlights the "human-AI gap"—a critical factor for achieving true AGI.
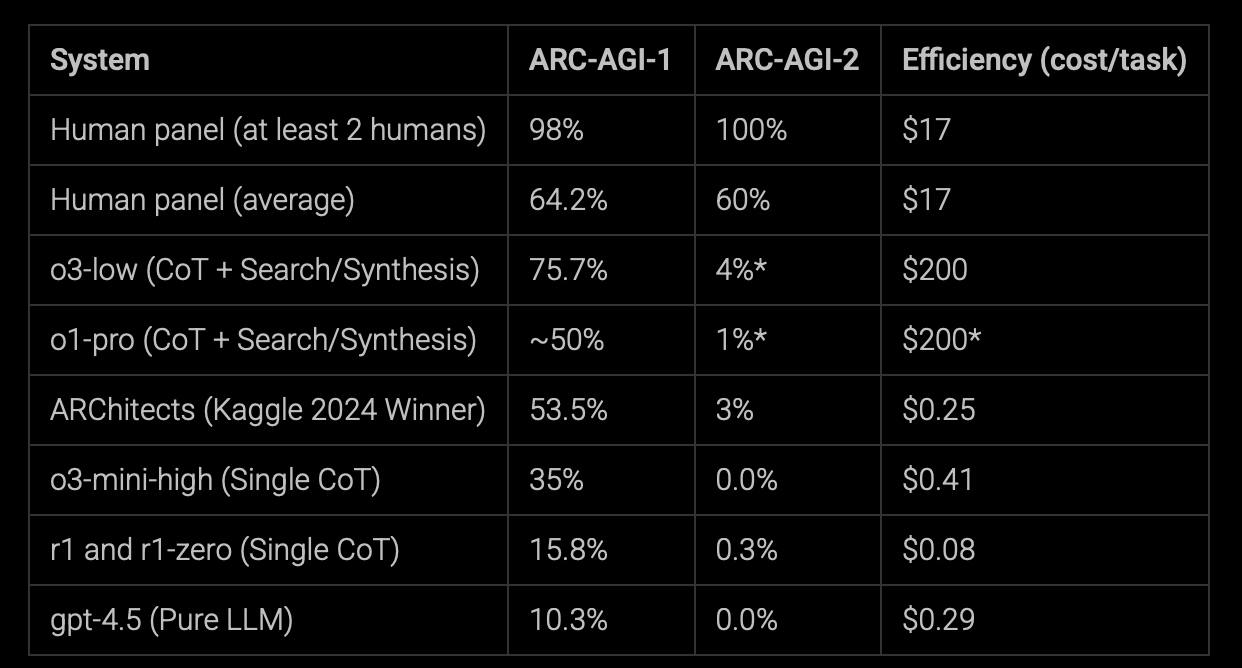
Benchmarks as of now, 24 March 2025!
STILL HARD FOR AI
Symbolic Interpretation

Compositional Reasoning

Contextual Rule Application

"Intelligence requires the ability to generalize from limited resources and apply knowledge in new and unexpected situations."
ARC-AGI-2 aims to pave the way toward AGI by addressing this gap.